
Testing PFLOTRAN-OGS on the latest AWS Graviton2 nodes
Introduction
At OGS we keep a close eye on the latest hardware available on Amazon Web Services (AWS), and when the latest generation of processors was announced, we were mainly attracted by the lowest pricing.
The new Graviton2 nodes (c6gn) make available 64 cores each, nearly twice the 36 cores on the Intel Xeon nodes (c5n) we have been using so far, and they are 30% cheaper.
But can PFLOTRAN-OGS exploit all the 64 cores of the Graviton2? And will the Graviton2 still scale well when using multiple-nodes?
Very recently, AWS resolved some issues preventing the assembly of Graviton2 nodes into virtual clusters, and we could finally carry out a complete test. It seems that Graviton2 will be able to reduce computing cost, without degrading significantly performance. Below we report our findings.
Performance and cost comparison of Graviton2 vs Intel Xeon Platinum nodes
The Graviton2 is a chip custom-made for AWS based on the ARMv8 technology [1]. It has 64 cores and it is available on nodes of the c6gn family. Here its performance is compared against the previous generation of AWS compute-optimised nodes (c5n), powered by Intel Xeon Platinum processors [2]. See the hardware comparison in the table below.
| Node Family | c6gn | c5n |
| CPU | Graviton2 | Xeon Platinum |
| Number of cores | 64 | 36 |
| Frequency | 2.5 GHz | 3.0 GHz |
| Number of sockets | 1 | 2 |
| Memory | 128 Gb | 192 Gb |
| Memory Bandwidth | 205 GB/sec | 220 GB/sec |
The c6gn and c5n nodes have similar memory bandwidth, achieved with a single socket by Graviton2, while the Xeon requires two. Both type of nodes can be interconnected via a low-latency 100 GB/sec network.
The comparison is done by running PFLOTRAN-OGS on a model for CO2 Storage in saline aquifers [3], using a refined mesh of 9.6 million active cells, and simulating only ten days of injection. The performance of the single nodes is first analysed, comparing solution times obtained by increasing the number of cores:
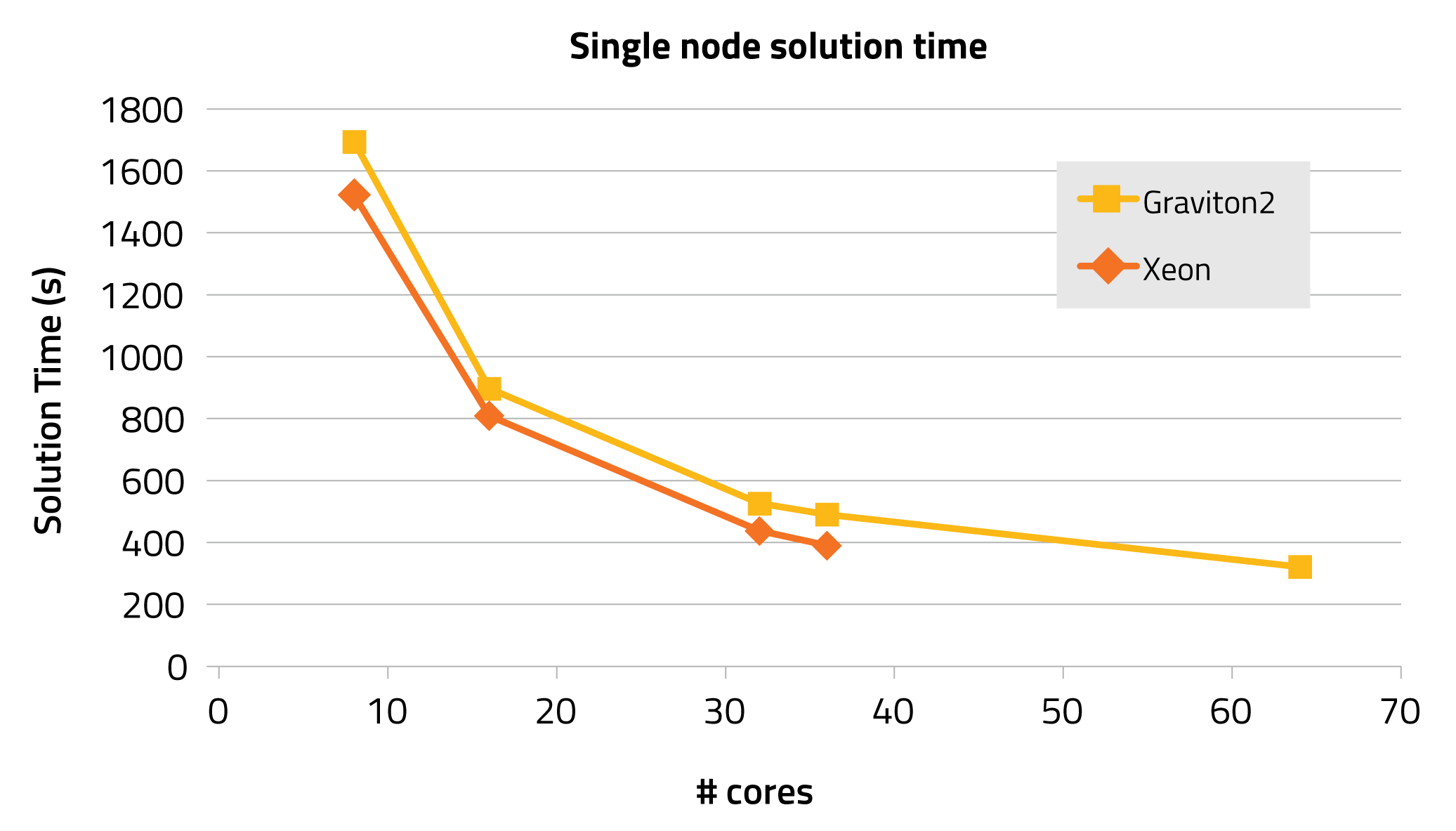
When considering the same number of cores, the Xeon is faster due to its higher frequency (3.0 GHz vs 2.5 GHz), however the Graviton2 achieves the best solution time when running with all its 64 cores. At the time of writing, the Graviton2 nodes cost $3.12/hour versus the $4.39/hour needed for the Xeon, providing a 30% saving while achieving a slightly better performance.
To complete the analysis, the performance on multi-node runs is assessed, using all available cores in each node. Below the solution time and cost per hour of simulation are given:
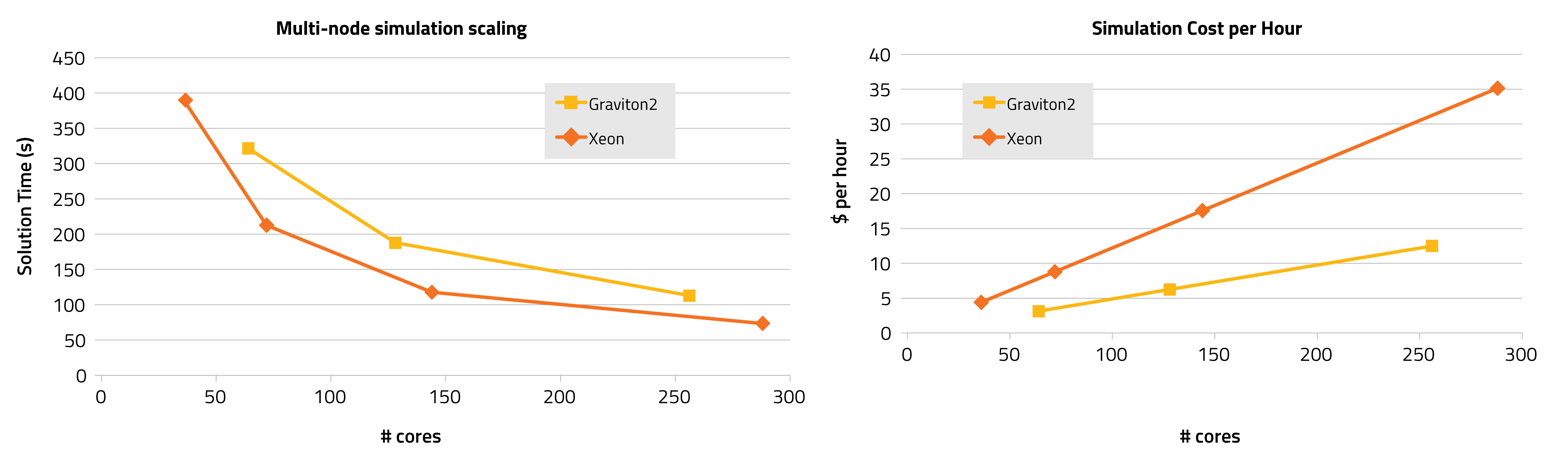
The solution time obtained by two Graviton2 nodes (128 cores) is very similar to the one obtained by two Xeon nodes (72 cores), and the same can be said when moving to 3 nodes, therefore the 30% saving is confirmed when moving to multi-node simulations. Given the same number of cores, the Xeon is still faster but also significantly more expensive. The last comparison of interest is on the scaling efficiency, useful in determining a sweet spot for the number of cores.
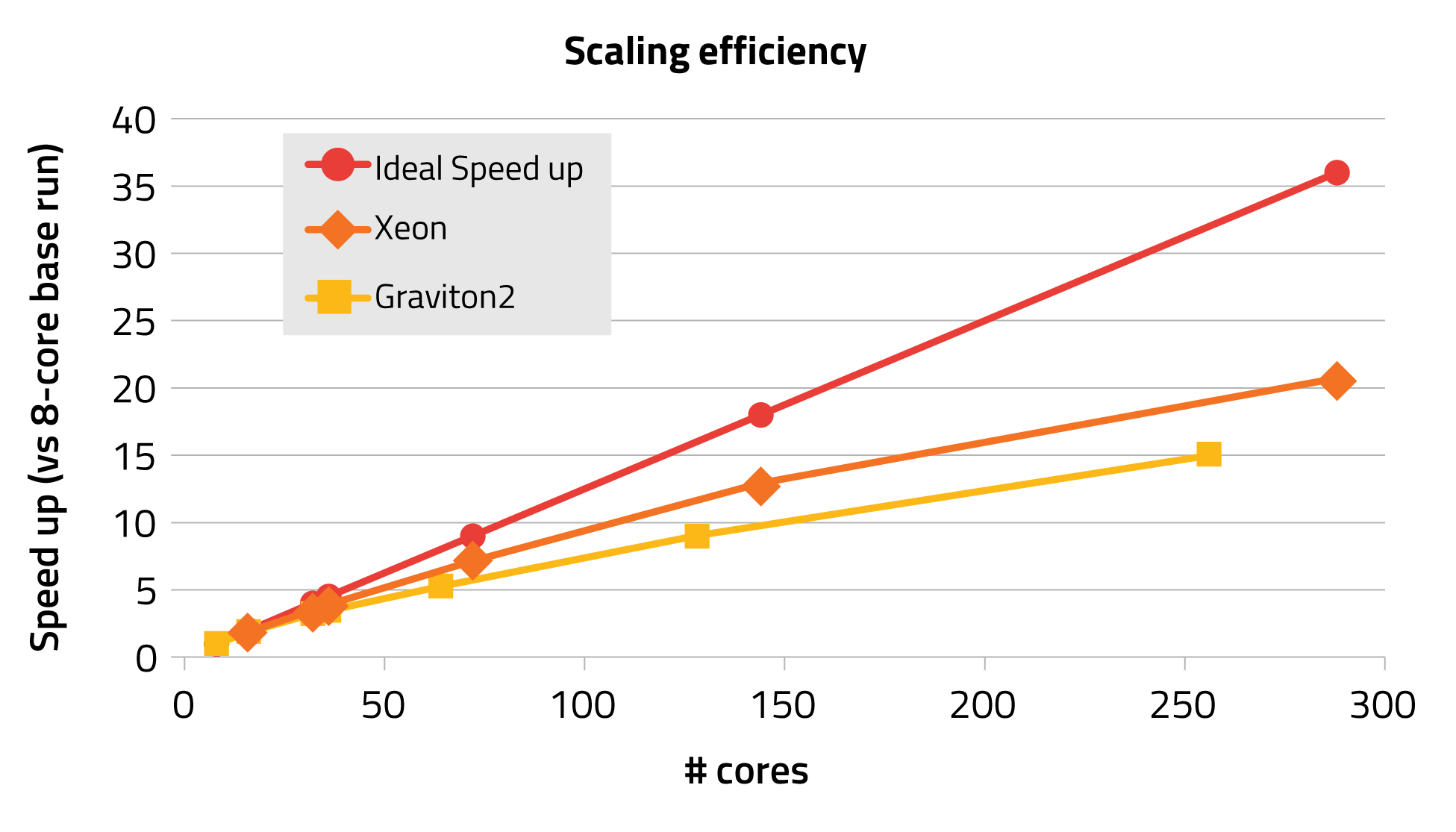
In the plot above, the speed up is reported versus a base run done with 8 cores, up to which linear scaling is observed (x8). The scaling efficiency of the Graviton2 is worse than the one observed when using the Xeon, however the decent scaling is still achieved up to 256 cores (8 x 15 = x120).
Conclusions
Unless the best solution time is the key parameter driving the selection of computational resources, the Graviton2 provides excellent value. For example, a x120 speed up can be achieved by spending $12/hour using 256 Graviton2 cores, saving 30% compared to the Xeon. To squeeze out up to the last drop of performance from PFLOTRAN-OGS, the Intel Xeon is still the best processor choice, due to better scaling and faster clocking.
References
[1] https://en.wikichip.org/wiki/annapurna_labs/alpine/alc12b00
FOLLOW US

RECENTS POSTS
- Hiring three new developers to work on the OGS CO2 and H2 Storage simulator
-
OpenGoSim will be exhibiting at the EAGE 2024 annual meeting in Oslo, 10th - 13th of June
OpenGoSim exhibiting at the EAGE 2024 annual meeting
09 June 2024 -
OpenGoSim will be exhibiting at the CCUS-2024 in Houston, 11th - 13th of March
OpenGoSim exhibiting at CCUS-2024
01 March 2024


